大数据Kafka学习(四) 文件存储与数据处理存储服务详解
在大数据生态中,Kafka不仅是一个高性能的消息队列,更是一个高效的分布式数据存储与处理系统。其独特的文件存储机制和数据处理能力,使其成为实时数据管道和流式应用的核心。本文将深入探讨Kafka的文件存储原理及其作为数据处理和存储服务的关键特性。
一、Kafka的文件存储机制
Kafka的文件存储设计以高性能、高吞吐量和持久性为核心目标。其存储架构主要基于以下核心概念:
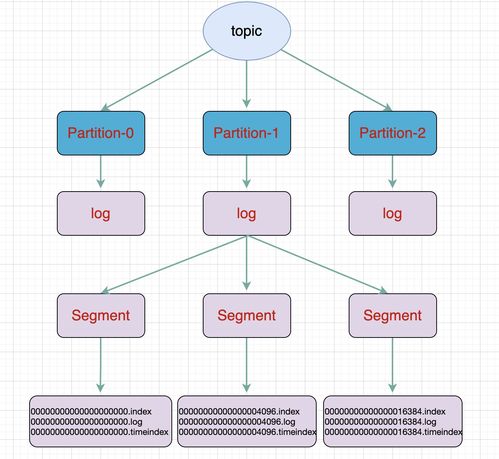
- 分区(Partition)与日志(Log):
- 每个Topic分为多个分区,每个分区在物理上对应一个日志文件目录。
- 分区是Kafka水平扩展和并行处理的基本单位。消息被追加(Append)到分区日志的末尾,保证了严格的顺序性。
- 日志段(Log Segment):
- Kafka不会将整个分区的数据写入单个巨大文件,而是将其切分为多个日志段文件。
- 每个日志段由两个主要文件组成:
- .log文件:存储实际的消息数据。
- .index文件:存储消息偏移量到物理文件位置的索引,用于快速定位和读取。
- 日志段文件遵循分段(Segment)和滚动(Rolling)策略。当当前活跃的日志段文件达到一定大小(如1GB)或时间(如7天)时,会关闭当前段并创建新的活跃段。这种设计便于旧数据的清理(根据保留策略删除整个段文件)和索引维护。
- 零拷贝(Zero-Copy)技术:
- 为了极致优化磁盘I/O和网络传输性能,Kafka大量使用了零拷贝技术。在消费者读取数据时,数据可以直接从磁盘文件通过DMA(直接内存访问)复制到网卡缓冲区,避免了在操作系统内核空间和用户空间之间的多次数据拷贝,显著降低了CPU开销和延迟,提升了吞吐量。
- 页缓存(Page Cache)优化:
- Kafka重度依赖操作系统的页缓存,而不是在JVM堆内维护缓存。写入和读取操作都首先与页缓存交互。这种设计使得:
- 写入:数据先写入稳定的页缓存,由操作系统异步刷盘,速度极快。
- 读取:如果数据在页缓存中,则直接读取内存,速度接近内存访问;同时利用了操作系统高效的文件预读(Read-ahead)和缓存管理机制。
- 这减少了JVM GC压力,并利用了OS成熟的内存管理能力。
二、Kafka作为数据处理与存储服务
Kafka的核心价值从“消息传递”演进为“流数据平台”,其数据处理和存储服务能力主要体现在以下方面:
- 高吞吐、低延迟的持久化存储:
- Kafka将每条消息持久化到磁盘,并提供可配置的复制机制(通过副本因子Replication Factor),保证数据的高可用性和容灾能力。
- 其顺序追加写入的模式,即使在机械硬盘上也能实现极高的写入吞吐量(通常达到数百万条/秒)。消费者可以以极低的延迟(毫秒级)读取已持久化的数据。
- 流式处理的数据源与中间站:
- Kafka是流处理框架(如Apache Flink、Apache Spark Streaming、Kafka Streams)的首选数据源和目的地。
- 处理流程通常为:
数据源 -> Kafka -> 流处理引擎 -> (处理结果) -> Kafka -> 下游应用或数据湖/仓。Kafka在其中扮演了缓冲、解耦和保证数据有序性的关键角色。
- Kafka Connect:可靠的数据集成服务
- Kafka Connect是一个用于在Kafka和外部系统(如数据库、数据仓库、文件系统)之间可靠、可扩展地传输数据的框架。
- Source Connector:将数据从外部系统导入Kafka Topic。
- Sink Connector:将Kafka Topic的数据导出到外部系统。
- 它简化了数据管道的构建,支持分布式运行、容错和 Exactly-Once 语义,是构建企业级数据管道的基础设施。
- Kafka Streams:嵌入式流处理库
- Kafka Streams是一个用于构建实时流处理应用的客户端库。它直接利用Kafka的存储和消费机制,提供:
- 高级流处理DSL:支持过滤、转换、聚合、连接(Join)等操作。
- 状态存储(State Store):将处理中间状态存储在本地RocksDB或内存中,并支持将状态备份到内部的Kafka Topic,实现容错。
- Exactly-Once处理语义:确保每条消息只被处理一次,结果精确无误。
- Kafka Streams应用是无状态的,其“状态”实际上存储在Kafka中,体现了Kafka作为存储系统的另一面。
- 数据回溯与重放(Replay)
- 由于数据被持久化存储并保留一定时间,消费者可以根据需要重置偏移量(Offset),重新消费历史数据。这是实现数据回溯分析、应用故障恢复、模型重新训练的基石。
###
Kafka的文件存储设计(分区、日志段、零拷贝、页缓存)是其高性能的基石。而基于此高效存储,Kafka超越了传统消息中间件,演化为一个集高吞吐数据持久化、流式处理集成、可靠数据连接和嵌入式流计算于一体的核心数据平台。理解其存储机制,是深入掌握Kafka作为现代数据处理和存储服务关键枢纽的前提。在构建实时数据管道、事件驱动架构和流处理应用时,Kafka的存储与处理服务能力是不可或缺的一环。
如若转载,请注明出处:http://www.52animal.com/product/38.html
更新时间:2026-04-16 20:56:17